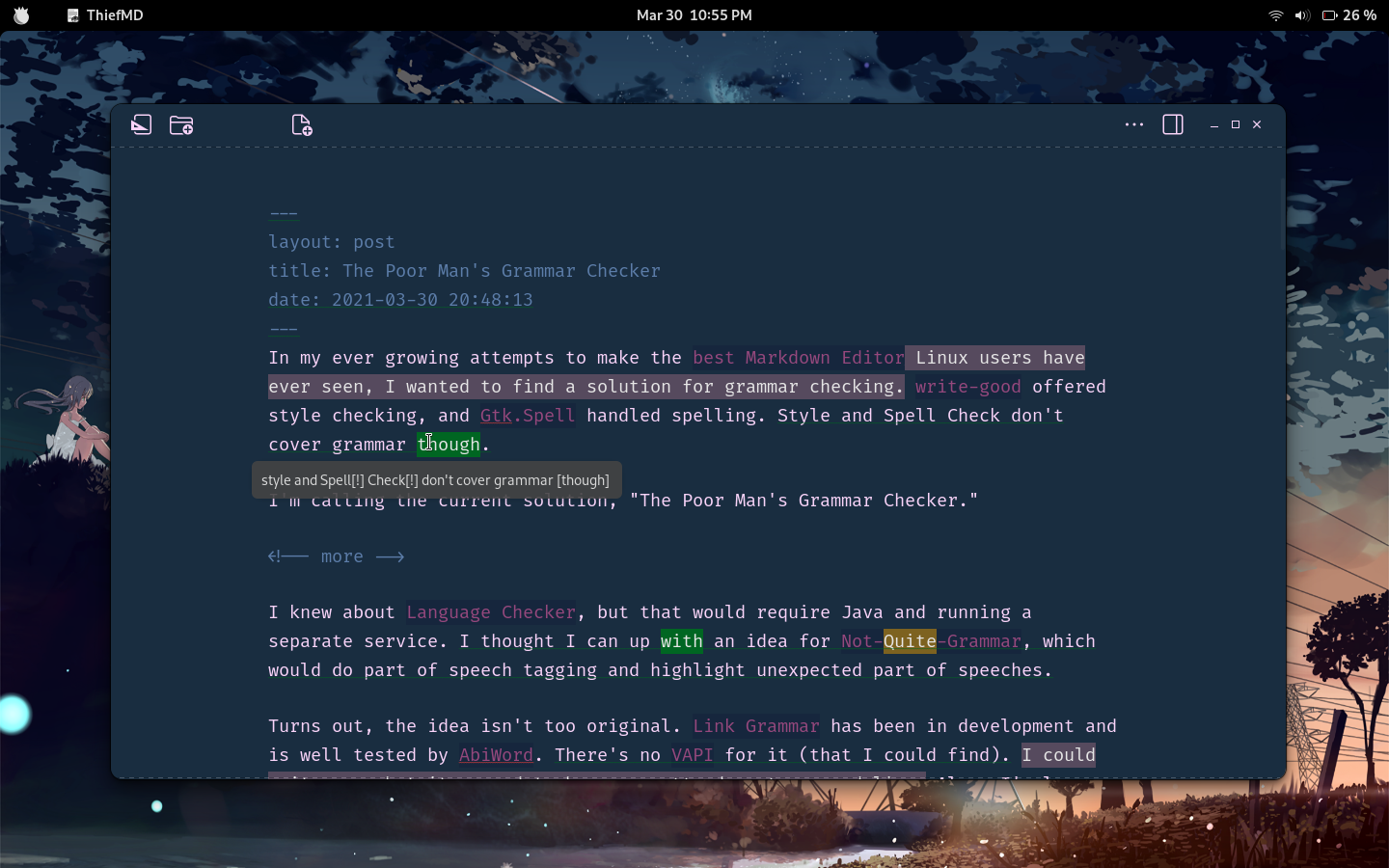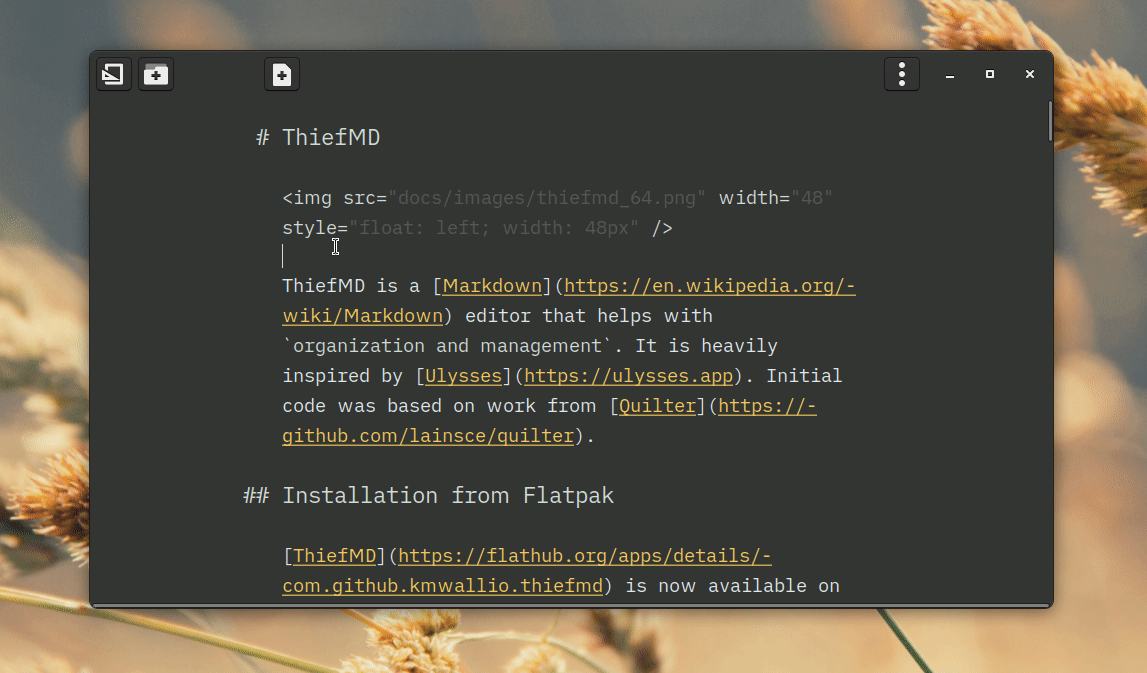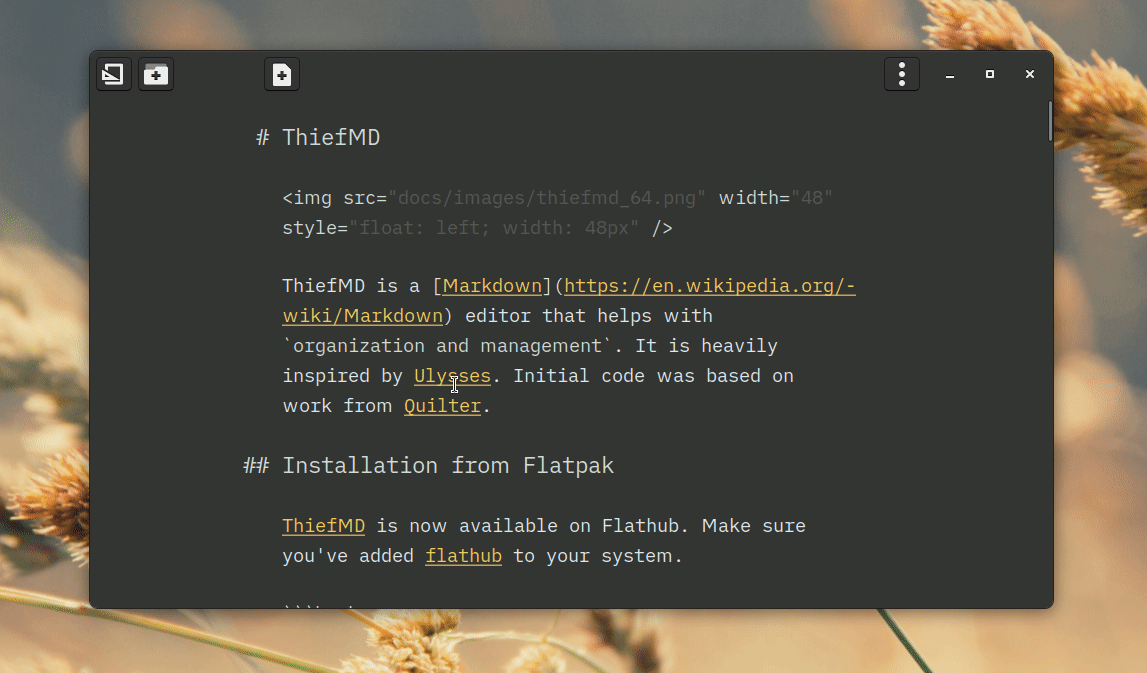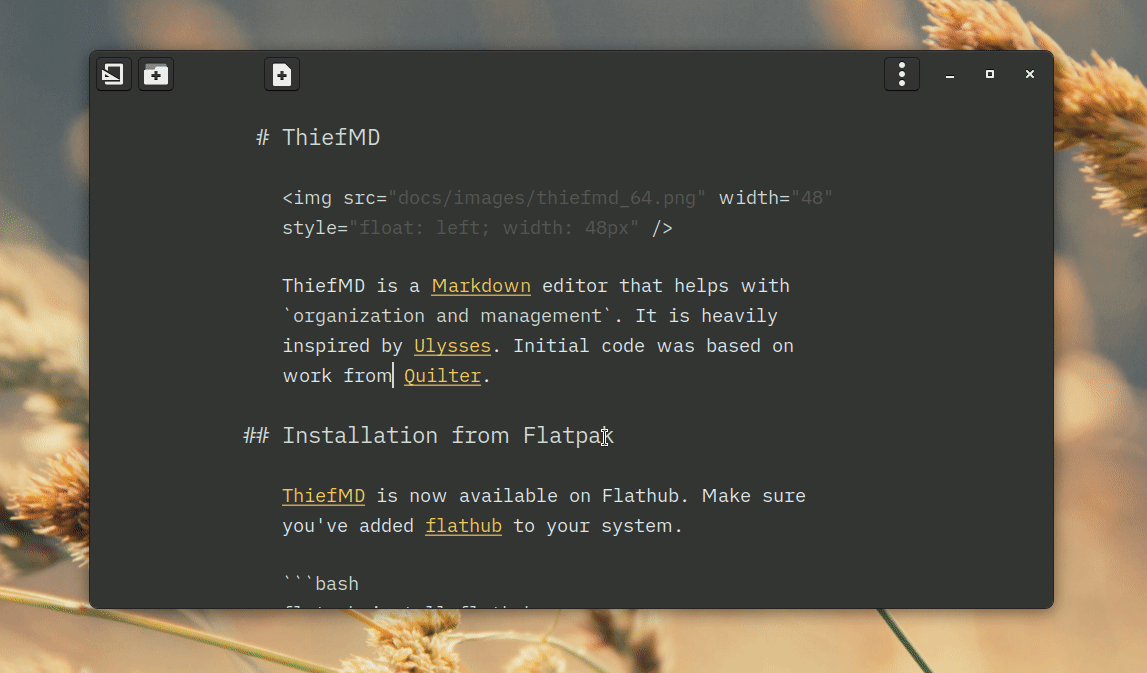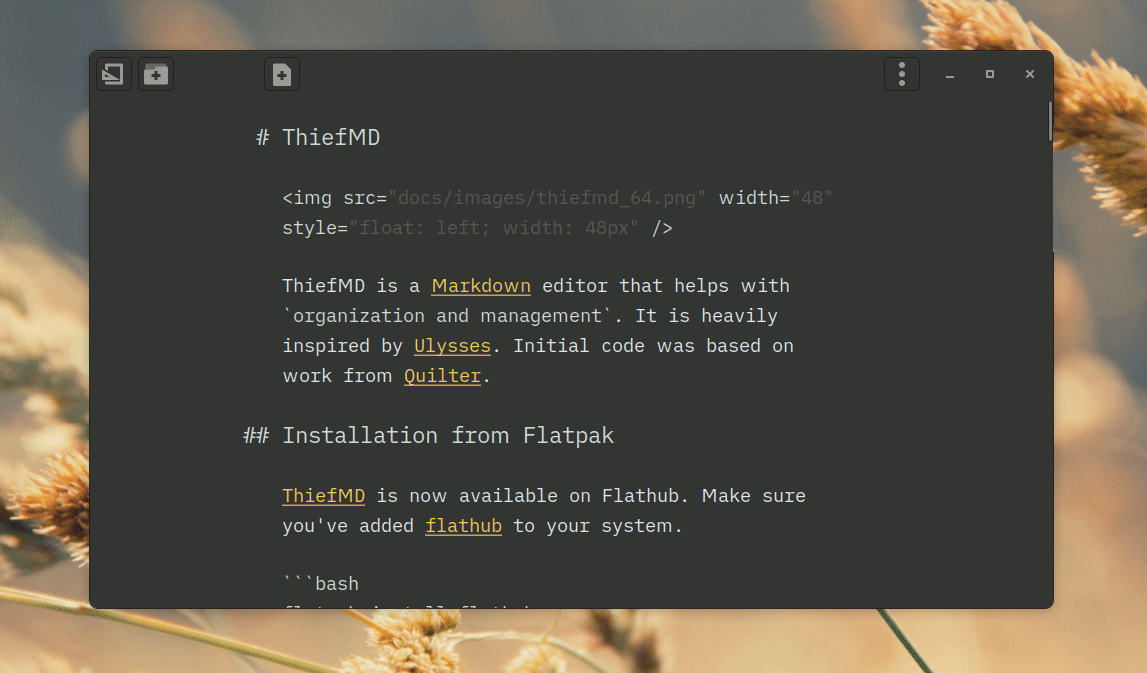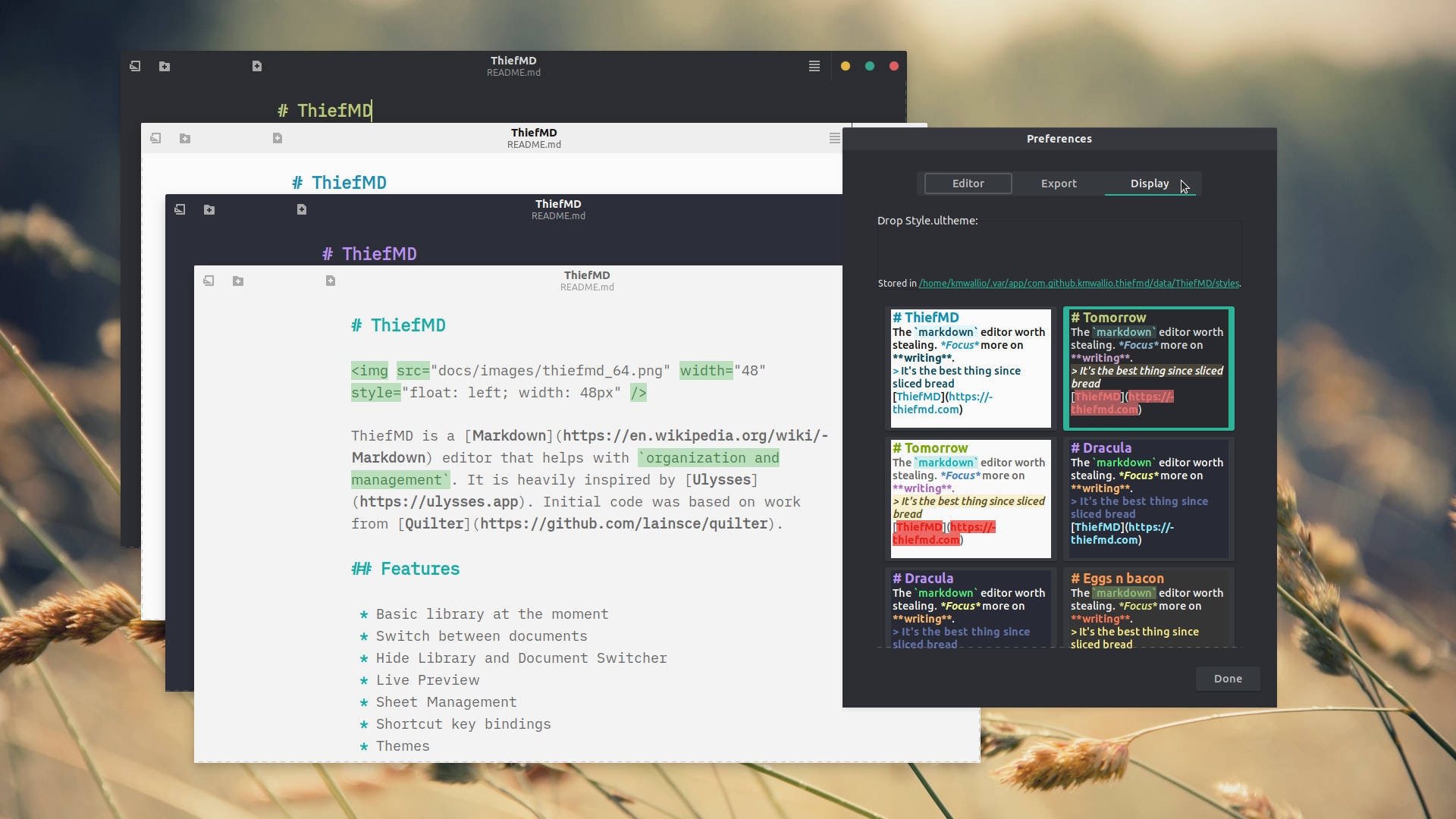
Not too much time has passed, but with staying inside due to COVID-19 and the Washington Wildfires, I’ve been making a lot of progress on my markdown editor app. This week I added Theme Support, Library Organization, Library Export, and possibly some other stuff.
I initially stole forked a project called Quilter. Quilter’s user experience is great, and I would compare it to iA Writer on macOS. I realized one of the applications I missed the most was Ulysses, and wanted something more like that.
Switching from macOS to Ubuntu has mostly been okay. My main reason for leaving was the laptop keyboard design 😝. As a software developer, a lot of applications I use are already cross-platform. Applications for “creatives” seems lacking in the Linux world. elementary OS is fixing that, but I like feature bloat.
I initially sent pull requests for my code changes into Quilter, but I really wanted to do some changes that would take the app in another direction. Thus, ThiefMD was born…
But here’s a brain dump of thoughts on how we got here…